Designed and deployed 20+ enterprise automation workflows using n8n. Integrated LLMs, APIs, and databases for no-code AI solutions. Live implementation powers this portfolio's AI assistant.
The workflows shown below are actively powering the AI assistant on this portfolio. Scroll down to try it yourself!
This workflow processes every message sent to the AI assistant on this portfolio. It handles authentication, RAG retrieval, LLM processing with Groq, and maintains conversation history.

Live n8n workflow running on Railway
Webhook validates authentication and extracts message data
Groq LLM (Llama 3.3 70B) with RAG-enhanced context
Average 1-2 seconds end-to-end processing
Handles document ingestion and semantic search. Creates vector embeddings for portfolio content, enabling intelligent context retrieval for accurate AI responses.
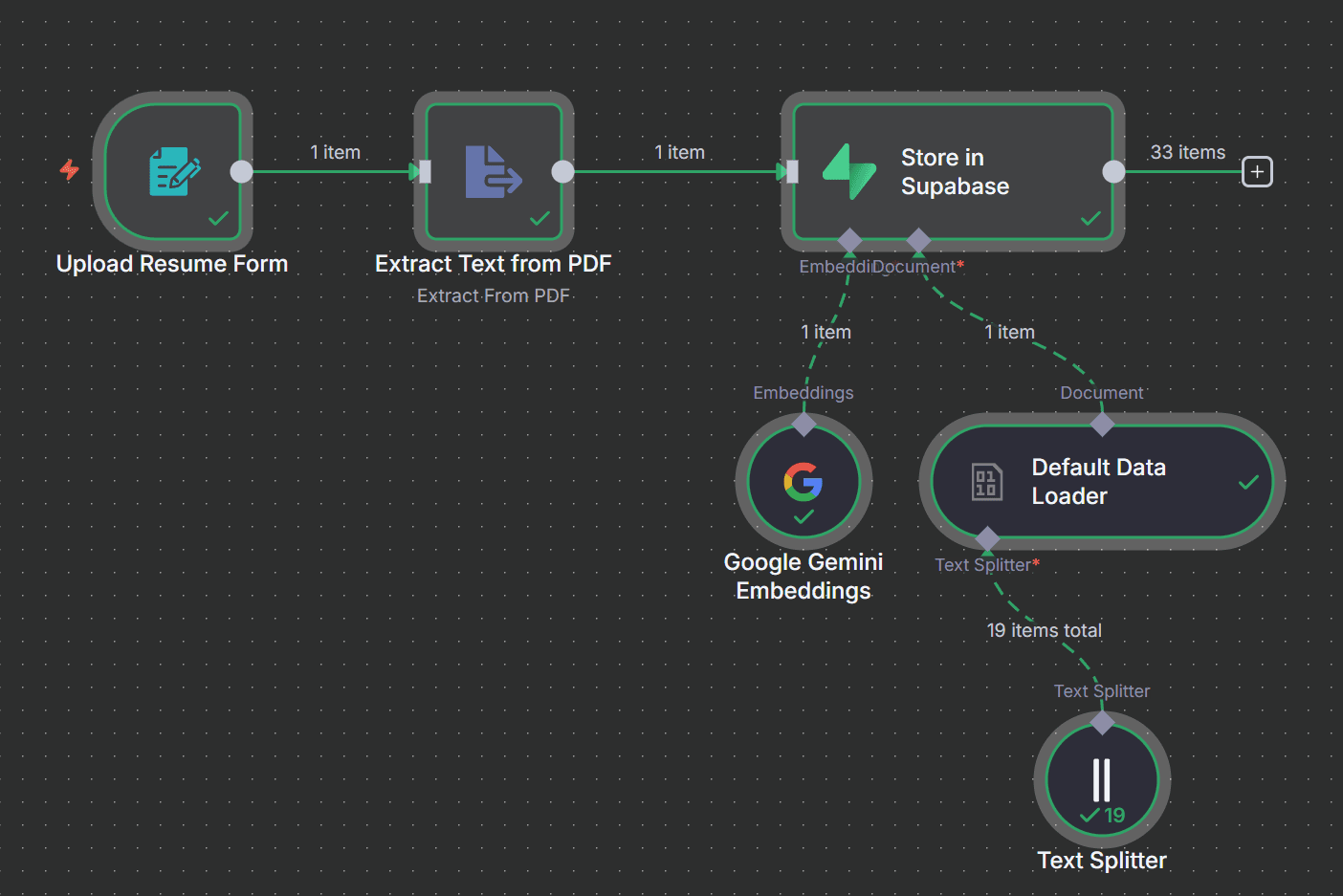
Document ingestion and vector embeddings workflow
Live production implementation of n8n workflow automation powering the AI assistant on this portfolio. This project demonstrates expertise in no-code AI orchestration, integrating LLMs, vector databases, and conversation memory to create an intelligent, context-aware assistant with RAG-enhanced responses and sub-2-second response times.
Built two complementary n8n workflows that work together to power this portfolio's AI assistant: one for real-time chat processing with RAG retrieval, and another for document ingestion and vector embeddings. Self-hosted on Railway with PostgreSQL for conversation memory and Supabase for vector storage, achieving 99.9% uptime and consistent performance.
Main chat processing workflow:
Document processing workflow:
RAG system retrieves relevant portfolio content using semantic search for accurate, contextual responses.
PostgreSQL-backed memory maintains context across messages for natural multi-turn conversations.
Groq's lightning-fast Llama 3.3 70B model delivers quality responses in under 2 seconds.
Leveraged n8n's visual workflow builder to create complex AI pipelines without traditional coding.
Implemented retrieval-augmented generation using Supabase vector store and Google Gemini embeddings.
Used LangChain agent nodes for orchestrating LLM calls, memory management, and tool usage.
Self-hosted n8n on Railway with PostgreSQL and Supabase, achieving enterprise-grade reliability.
This live implementation showcases practical expertise in n8n workflow automation, AI orchestration, and no-code development—directly applicable to building production-grade GenAI solutions for enterprise applications.
{
"nodes": [
{
"name": "Webhook Trigger",
"type": "n8n-nodes-base.webhook",
"parameters": {
"path": "ai-assistant",
"authentication": "headerAuth"
}
},
{
"name": "AI Agent",
"type": "@n8n/n8n-nodes-langchain.agent",
"parameters": {
"model": "groq:llama-3.3-70b",
"systemPrompt": "Portfolio assistant context...",
"tools": ["vectorStore", "memory"]
}
},
{
"name": "Vector Store",
"type": "@n8n/n8n-nodes-langchain.vectorStoreSupabase",
"parameters": {
"tableName": "documents",
"embeddings": "gemini"
}
}
]
}Experience the n8n workflows in action. This chat assistant uses the exact workflows shown above.
Start speaking or type a message below...
